AI 預測在運動投注的邏輯架構
AI 運動預測的核心是一條五步驟管線:收集歷史賽事數據、清理資料、做特徵工程、訓練機器學習模型,最後拿預測勝率比對即時賠率找出正期望值的投注。相較只靠人工經驗分析,機器學習平均能把預測精準度再提高約 15%。本文以 NBA 為例,完整拆解每一步的實作邏輯。
想直接看回測成果?模型在 13,000+ 場比賽、53 次迭代後的實際勝率與獲利曲線,整理在AI 模型表現驗證頁。
預測管線總覽:五個步驟
一條管線,五個步驟
從原始數據到正期望值投注——資料沿著管線流動。
抓取賽季數據
從 Basketball-Reference 與 stats.nba.com 收集 300 萬筆以上歷史資料
數據清理
處理缺失值、重複值、離群值,統一格式確保資料品質
特徵工程
萃取 Elo Rating、近期表現、傷兵、PER 等預測力最強的特徵
模型訓練
隨機森林、邏輯迴歸等模型反覆回測,找出最高測試精度
賠率比對找價值
用 AI 勝率對照即時賠率計算期望值,只下注正 EV 的盤口
抓取 NBA 賽季數據
資料來源是 Basketball-Reference 與 stats.nba.com,涵蓋 1946 年至今每一場比賽,總計超過 300 萬筆球隊與球員紀錄:勝敗場、總得分、籃板、助攻、失誤、抄截、三分命中率、罰球數等。兩個來源都支援自訂日期範圍,技術上用 Python 的 requests 讀取 HTML,再以 Pandas 的 pd.read_html() 或 BeautifulSoup 解析出需要的表格。
抓回來的原始欄位會先做欄名標準化,讓後續清理與特徵工程有一致的 schema:
COLUMN_MAP = {
'PName': 'Player_Name', # 球員姓名
'POS': 'Position', # 位置
'Team': 'Team_Abbreviation',
'GP': 'Games_Played',
'W': 'Wins',
'L': 'Losses',
'Min': 'Minutes_Played',
'PTS': 'Total_Points',
'FG%': 'Field_Goal_Percentage',
'3P%': 'Three_Point_FG_Percentage',
'FT%': 'Free_Throw_Percentage',
'REB': 'Total_Rebounds',
'AST': 'Assists',
'TOV': 'Turnovers',
'STL': 'Steals',
'BLK': 'Blocks',
# ... 共 29 個欄位,含 OREB / DREB / PF / FP / DD2 / TD3
}
數據清理
數據清理直接決定模型上限。原始資料常見輸入錯誤、缺失、重複與離群值,必須先處理乾淨。這裡有兩個容易被忽略的關鍵:一是移除「會洩漏勝負結果」的欄位,避免模型作弊式地學到答案;二是刪除高度相關的重複特徵(例如投籃命中率、兩分命中率、三分命中率彼此重疊),降低特徵間的共線性。
缺失數據處理
刪除缺失值、合理填補,或用模型推估補值,避免訓練資料出現空洞。
重複數據處理
偵測並刪除重複條目,確保每筆比賽與球員紀錄都是唯一的。
離群值處理
用統計方法或演算法找出異常極端值,避免單場暴走數據扭曲模型。
數據一致性處理
統一球員名稱拼寫、轉換不同來源的格式,讓所有資料說同一種語言。
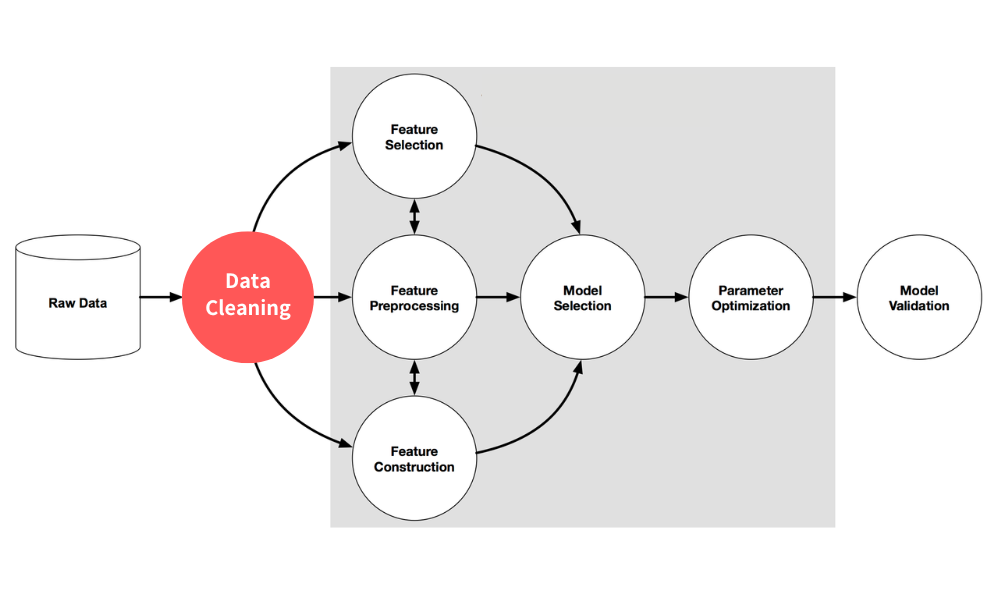
特徵工程:五個關鍵特徵
特徵工程的本質是把兩支球隊的能力值拆成可以比較的數字,找出決定勝負的因素與權重——不看隊名與名氣,只看純數據的絕對值。NBA 深度學習實作中,以下五個特徵對比賽結果的預測力最強。
特徵預測力排序
相對化的球隊統計(Elo)預測力遠勝個別球員效率(PER)——模型最核心的取捨。
1. Elo Rating:用比賽結果衡量球隊實力
Elo Rating 只需要每場比賽的最終比分、地點與時間就能運作。贏球加分、輸球扣分,爆冷獲勝或大分差獲勝會拿到更多分;它是零和系統,一隊加幾分對手就扣幾分,所有球隊的初始分通常設在中位數 1500。每場賽後的更新公式:
Elo_new = Elo_old + K × (Result − WinProbability) Elo_old 目前的 Elo Rating K 調整參數:K 越大,分數變動越快 Result 實際結果(勝 = 1,敗 = 0) WinProbability 由雙方 Elo 差換算出的預測勝率
Elo 也會跨賽季傳承——強隊通常維持強勢、弱隊很少瞬間翻身,所以新賽季的起始分是把上季期末分數向聯盟平均(1505)回歸 25%:
Elo_next_season = (R × 0.75) + (0.25 × 1505) R = 球隊上一個賽季的期末 Elo Rating
把任三支球隊的 Elo 隨時間畫出來,可以直接看出整季實力消長:勇士與騎士在總冠軍賽交手的年份 Elo 同步衝上峰值;西區整體比東區艱難,也反映在勇士「品質勝利」帶來的額外 Elo 加分;而冠軍賽季後的陣容流失與傷病,同樣會在曲線上快速下滑。
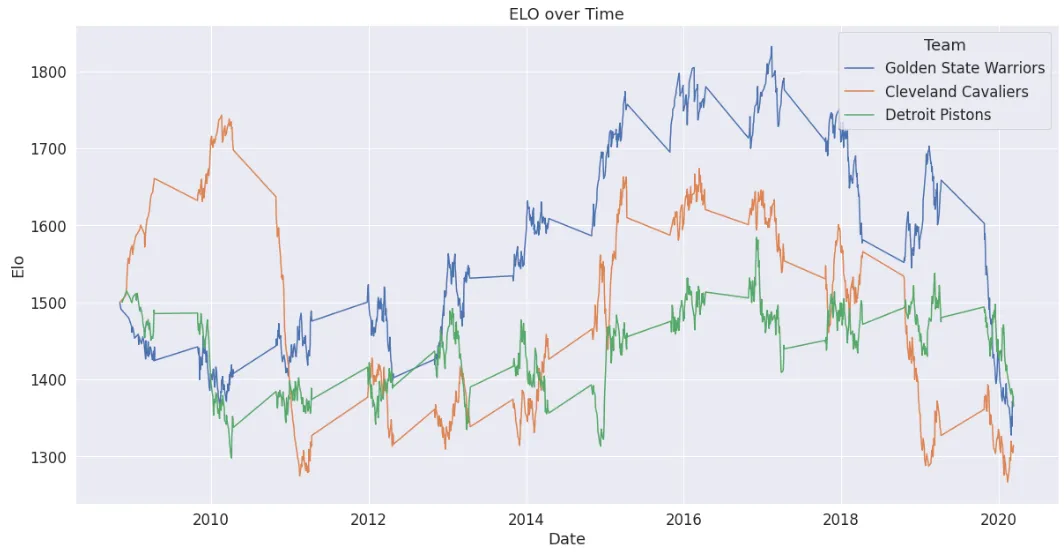
2. 近期球隊表現(最近 10 場平均)
把每隊最近 10 場的得分、籃板、助攻、失誤、封蓋、抄截取平均,存成新的特徵欄。重點在挑特徵:用相關性分析、主成分分析(PCA)與資訊增益篩出資訊量最高的欄位。若要進一步捕捉趨勢與季節性,可疊加時間序列模型(ARIMA、LSTM),或直接交給 SVM、決策樹、隨機森林等模型去學特徵之間的非線性關係。
3. 近期球員表現(最近 10 場平均)
球隊層級之外,個別球員的近況同樣是訊號。從 nba.com/stats 取得逐場明細後,對每位球員算出近 10 場平均。以兩位球星為例:
| 球員 | 得分 | 籃板 | 助攻 | 失誤 | 封蓋 | 抄截 |
|---|---|---|---|---|---|---|
| 勒布朗·詹姆斯 | 28.5 | 7.8 | 7.2 | 2.3 | 1.1 | 1.5 |
| 史蒂芬·柯瑞 | 31.2 | 5.6 | 6.8 | 2.1 | 0.3 | 1.7 |
不同球員的價值體現在不同欄位(得分手 vs 籃板型中鋒),特徵選擇同樣靠相關性分析、PCA 與資訊增益決定。
4. 球員賽季表現(前賽季與本賽季)
單看平均數字會失真——球員會受傷、進出輪換,模型更在意的是「單場表現相對自身平均水準的偏離」。完整評估必須同時納入五個面向:
平均統計數據
得分、助攻、籃板、抄截、封蓋與失誤,需搭配位置與戰術解讀,避免被表面數字誤導。
傷兵狀態
受傷部位與預估復原時間直接影響出賽與復出後的表現波動,是模型的關鍵輸入。
出場時間
先發與替補的上場分鐘差異會放大或壓縮統計數據,短時間高產出代表高效率。
位置與比賽風格
得分後衛與中鋒的職責不同,球隊戰術(團隊傳導 vs 個人單打)也會改變數據樣貌。
勝負情境
領先收尾會放慢節奏壓低數據、落後追分會衝高數據,勝敗脈絡必須一併納入。
5. 球員效率評級(PER)
如同 Elo 之於球隊,Hollinger 的 PER 把看似不相關的統計整合成單一指標來「相對化」球員表現。NBA 球員的數據很容易被上場時間、對位對象(替補 vs 先發)放大或壓縮,PER 用「每分鐘」做歸一化解決這個問題——對各項攻防數據加權後,再乘上上場分鐘數的倒數:
PER = ( FGM × 85.910 + STL × 53.897 + 3PTM × 51.757
+ FTM × 46.845 + BLK × 39.190 + OREB × 39.190
+ AST × 34.677 + DREB × 14.707 − PF × 17.174
− FT_Miss × 20.091 − FG_Miss × 39.190 − TOV × 53.897
) × (1 / Minutes)數據分析與模型訓練
分析的核心問題有兩個:Elo 是否真的與其他統計相關、媒合正確?以及用球隊統計(Elo)還是球員統計(PER)預測比賽結果更準?
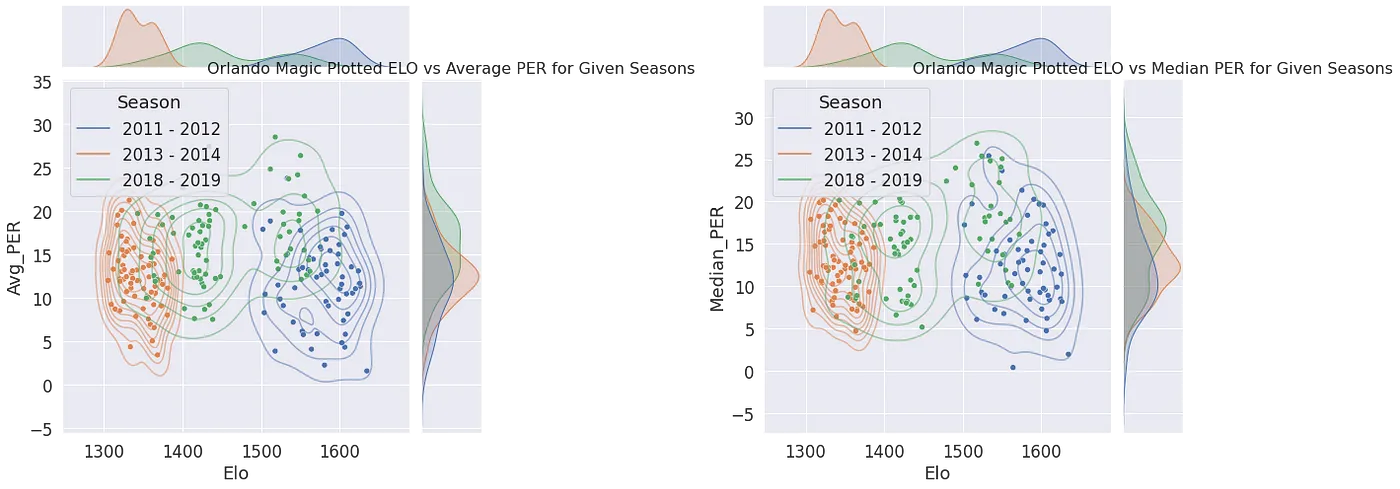
先看整個聯盟每季的 Elo 分佈密度:接近常態分佈代表聯盟戰力均衡,出現長尾則代表「超級球隊」成形。再追蹤單一球隊,平均得分越高 Elo 通常越高,但相似得分下 Elo 仍有很大變異——把得分「相對於對手、相對於聯盟平均」之後,相關性才真正穩定。這證明 Elo 之所以比原始得分更會預測勝負,正因為它是相對化的統計。反觀 PER:把球隊的 PER 總和、平均、中位數對上 Elo 衡量的球隊實力,相關性都很弱——球員效率高不等於得分多,而對戰中真正決定勝負(進而推動 Elo)的是相對得分。
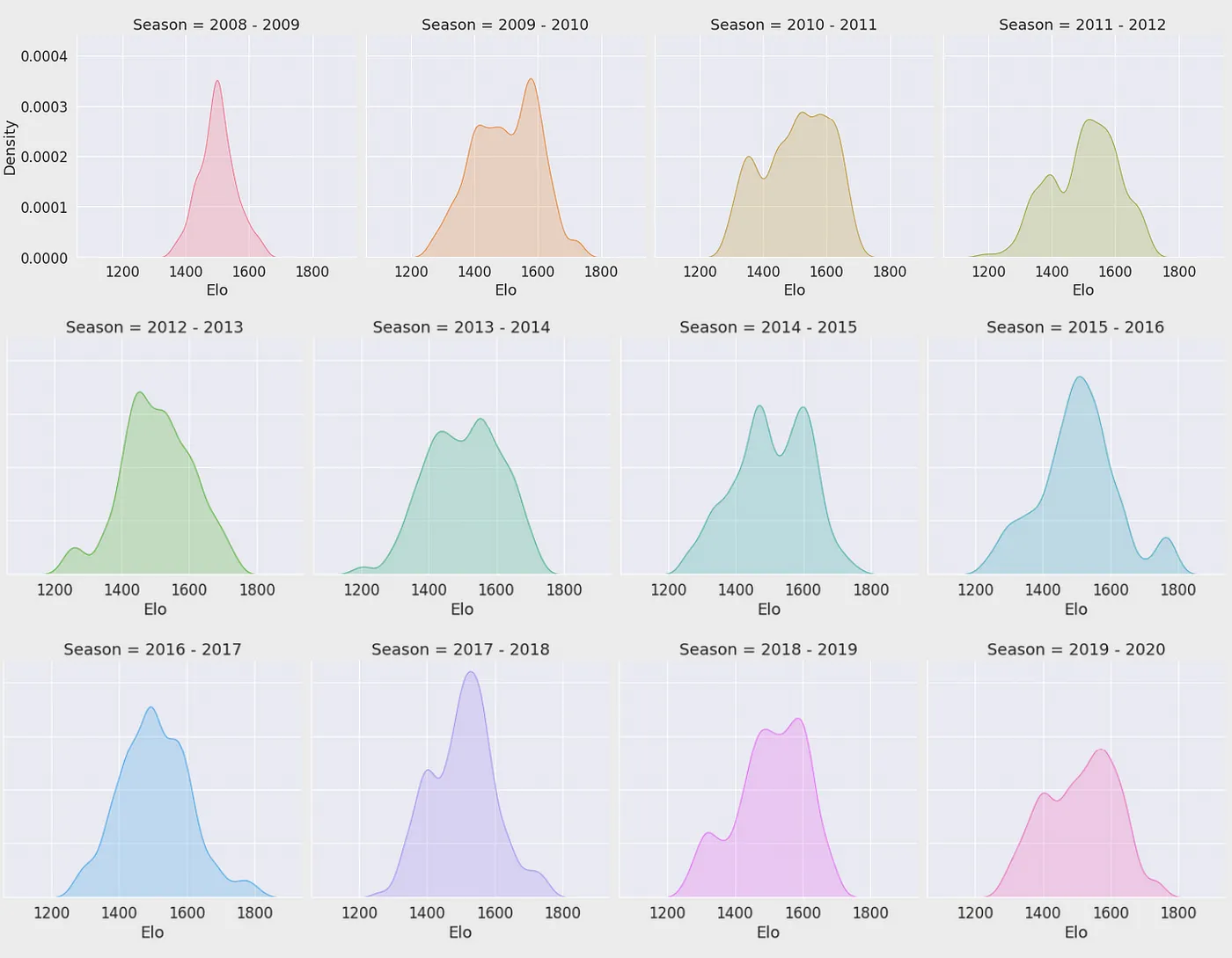
兩個核心結論
- 相對化才穩定:得分換成「相對對手、相對聯盟」後,與勝負的相關性才真正成立。
- 球隊 > 球員加總:PER 總和與球隊實力相關性很弱,球員效率高 ≠ 球隊會贏。
測試精度 vs 理論天花板
業界最強 NBA 預測命中率約 70%;隨機森林 67.15% 已逼近上限——剩餘空間在模型選擇而非調參。
以球員得分預測比賽結果時,用線性迴歸(預測連續分數)而非邏輯迴歸(只預測勝負),再把每隊預測得分加總比較。58.66% 的準確率印證了前面的觀察:球員綜合表現變異太大,不如球隊層級的表現一致。最終以 RandomSearchCV 調參的隨機森林拿到 67.15% 的最高測試精度——而業界最強的 NBA 預測模型命中率天花板也只在 70% 左右,代表模型已逼近理論上限。後續的優化方向是把時間花在模型選擇(SGD 分類器、線性判別分析、卷積網路、樸素貝葉斯)而非調參。
賠率比對:從預測勝率到正期望值
模型勝率本身不會賺錢,獲利公式需要三個要素:深度學習的預測勝率、即時的賠率,以及回測過的投注策略。把 AI 勝率對上市場賠率算出期望值(EV),只在 EV 為正時出手:
EV = (AI 預測勝率 × 歐式賠率) − 1 EV > 0 → 長期下注可期待正報酬(價值投注) EV < 0 → 長期下注會虧損,直接跳過 範例:AI 勝率 58%、賠率 1.90 EV = (0.58 × 1.90) − 1 = +0.102 → 每注期望 +10.2%
這套方法不限於 NBA,籃球、棒球、足球、冰球、網球都適用。模型在真實賽事的命中率與獲利單位數,可以在AI 模型表現驗證逐月檢視;下注前的期望值與串關賠率試算,則可以用投注計算機快速完成。
同一套架構,涵蓋全球主流聯賽
特徵工程的精神是「比較能力值、不看隊名」,所以同一套管線可以平移到不同運動:目前涵蓋 NBA、MLB、五大足球聯賽、歐洲賽事與 NHL,未來將持續擴展到更多聯賽。
 NBA
NBA MLB
MLB 英超
英超 西甲
西甲 德甲
德甲 義甲
義甲 法甲
法甲 歐冠
歐冠 歐霸
歐霸 MLS
MLS NHL
NHL
結論與下一步
- 相對化的統計贏過原始數字:Elo 比平均得分準、得分比 PER 總和準,因為勝負本來就是相對的。
- 球隊層級的特徵比球員加總穩定,是模型主力訊號;球員近況作為輔助特徵。
- 67.15% 的測試精度已逼近 NBA 預測約 70% 的理論天花板,剩餘空間在模型選擇而非無止盡調參。
- 預測勝率必須搭配賠率比對與正 EV 紀律,才會轉化成長期獲利。
參考文獻與資料來源
本文方法與資料皆可公開查證,歡迎深入閱讀原始研究:
看懂演算法之後,用數據管好自己的注單
免費記錄每一筆投注,自動算出勝率、ROI 與資金曲線——讓你像模型一樣,用回測檢視自己的投注策略。