La lógica detrás de la predicción con IA en las apuestas deportivas
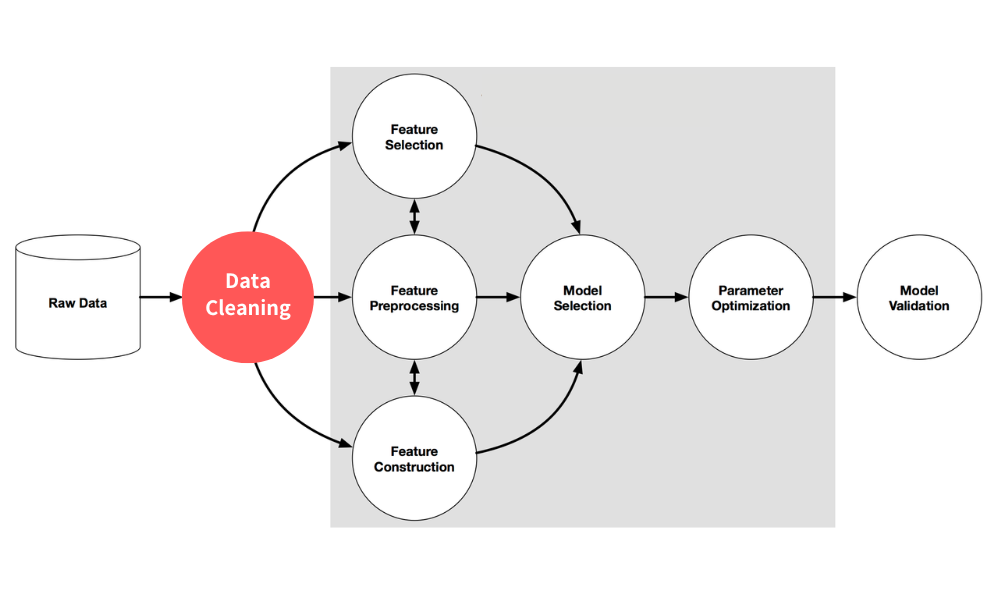
La predicción deportiva con IA se reduce a un pipeline de cinco etapas: recopilar datos históricos de partidos, limpiarlos, crear características, entrenar un modelo de aprendizaje automático y, finalmente, comparar las tasas de acierto previstas con las cuotas en vivo para detectar apuestas de EV positivo. Comparado con confiar solo en la intuición humana, el aprendizaje automático eleva la precisión de la predicción en torno a un 15% de media. Este artículo usa la NBA como ejemplo práctico y desglosa la lógica de implementación de cada paso.
¿Quieres ver primero los resultados del backtest? La tasa de acierto real del modelo y la curva de beneficio a lo largo de más de 13.000 partidos y 53 iteraciones se exponen en la páginaRendimiento del Modelo de IA.
El pipeline de predicción: cinco pasos de un vistazo
Una canalización, cinco etapas
De los datos brutos a las apuestas con EV positivo — observa cómo los datos fluyen por la canalización.
Recopilar datos de la temporada
Extraer más de 3 millones de registros históricos de Basketball-Reference y stats.nba.com
Limpiar los datos
Tratar valores faltantes, duplicados y atípicos, y estandarizar formatos para garantizar la calidad de los datos
Diseñar características
Extraer las características más predictivas — Calificación Elo, forma reciente, lesiones, PER y más
Entrenar el modelo
Hacer backtest de bosques aleatorios, regresión logística y otros modelos para hallar la mayor precisión de prueba
Comparar cuotas en busca de valor
Calcular el valor esperado contrastando las tasas de acierto de la IA con las cuotas en vivo, apostando solo en líneas con EV positivo
Extracción de datos de la temporada de la NBA
Los datos provienen de Basketball-Reference y stats.nba.com, y abarcan todos los partidos desde 1946 — más de 3 millones de registros de equipos y jugadores: victorias y derrotas, puntos totales, rebotes, asistencias, pérdidas, robos, porcentaje de triples, intentos de tiros libres y más. Ambas fuentes admiten rangos de fechas personalizados; técnicamente, leemos el HTML con requests de Python y luego extraemos las tablas que necesitamos usando elpd.read_html() de Pandas o BeautifulSoup.
Las columnas brutas se normalizan primero para que la limpieza y la ingeniería de características posteriores compartan un esquema coherente:
COLUMN_MAP = {
'PName': 'Player_Name', # nombre del jugador
'POS': 'Position', # posición
'Team': 'Team_Abbreviation',
'GP': 'Games_Played',
'W': 'Wins',
'L': 'Losses',
'Min': 'Minutes_Played',
'PTS': 'Total_Points',
'FG%': 'Field_Goal_Percentage',
'3P%': 'Three_Point_FG_Percentage',
'FT%': 'Free_Throw_Percentage',
'REB': 'Total_Rebounds',
'AST': 'Assists',
'TOV': 'Turnovers',
'STL': 'Steals',
'BLK': 'Blocks',
# ... 29 columnas en total, incl. OREB / DREB / PF / FP / DD2 / TD3
}
Limpieza de datos
La limpieza de datos marca el techo de lo que el modelo puede lograr. Los datos brutos están plagados de errores de entrada, valores faltantes, duplicados y valores atípicos que primero deben depurarse. Dos puntos fáciles de pasar por alto son los más importantes: primero, elimina cualquier columna que filtre el resultado final para que el modelo no pueda hacer trampa hacia la respuesta; segundo, retira las características redundantes muy correlacionadas (los porcentajes de tiros de campo, de dos y de tres puntos se solapan, por ejemplo) para reducir la multicolinealidad.
Tratar los datos faltantes
Eliminar, imputar con criterio o estimar con el modelo los valores faltantes para que el conjunto de entrenamiento no tenga huecos.
Eliminar duplicados
Detectar y eliminar entradas duplicadas para que cada registro de partido y jugador sea único.
Tratar los valores atípicos
Usar métodos estadísticos o algoritmos para marcar valores extremos de modo que un solo partido excepcional no sesgue el modelo.
Garantizar la coherencia
Estandarizar la grafía de los nombres de los jugadores y conciliar los formatos entre fuentes para que todos los datos hablen un mismo idioma.
Ingeniería de características: cinco características clave
En esencia, la ingeniería de características convierte la capacidad de cada equipo en números comparables, sacando a la luz los factores y pesos que deciden un partido — ignorando los nombres y la reputación de los equipos, mirando solo los números duros. En una implementación de aprendizaje profundo para la NBA, las cinco características siguientes son las de mayor poder predictivo sobre los resultados de los partidos.
Características clasificadas por poder predictivo
Las métricas relativizadas del equipo (Elo) superan con creces la eficiencia individual del jugador (PER) — la compensación más decisiva del modelo.
1. Rating Elo: medir la fuerza del equipo a partir de los resultados
El rating Elo solo necesita el marcador final, la ubicación y la fecha de cada partido para funcionar. Las victorias suman puntos, las derrotas los restan, y una sorpresa o una victoria por paliza otorga más; es un sistema de suma cero, así que los puntos que gana un equipo los pierde el rival. Cada equipo suele empezar en la mediana de 1500. La fórmula de actualización tras el partido es:
Elo_new = Elo_old + K × (Result − WinProbability) Elo_old Elo Rating actual K parámetro de ajuste: cuanto mayor es K, más rápido cambian las valoraciones Result resultado real (victoria = 1, derrota = 0) WinProbability tasa de victoria prevista derivada de la diferencia de Elo entre los dos equipos
El Elo también se arrastra entre temporadas — los equipos fuertes tienden a seguir siéndolo y los débiles rara vez cambian de un día para otro — así que cada nueva temporada comienza regresando el rating final de la temporada anterior un 25% hacia la media de la liga de 1505:
Elo_next_season = (R × 0.75) + (0.25 × 1505) R = la valoración Elo final del equipo de la temporada pasada
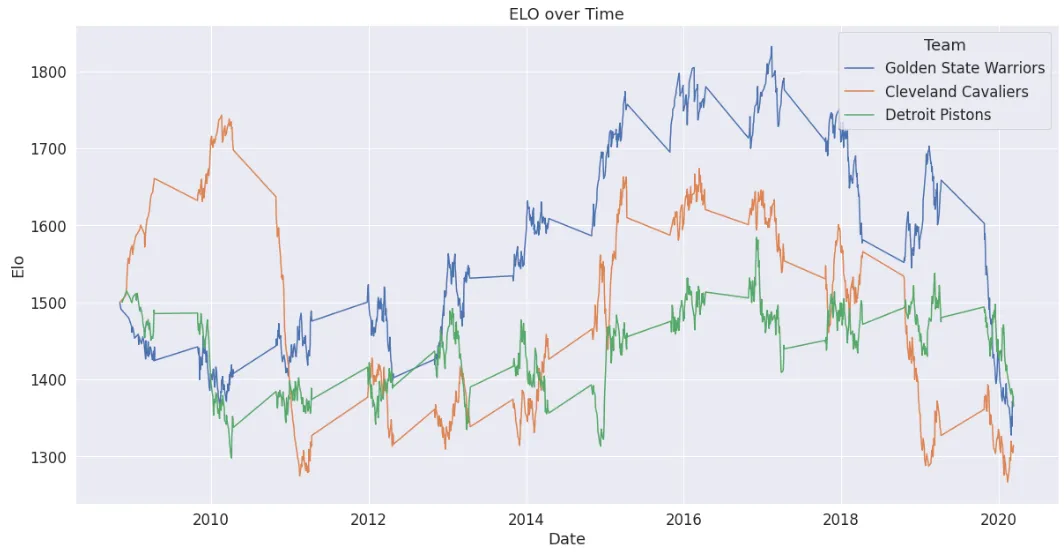
Grafica el Elo de tres equipos cualesquiera en el tiempo y el flujo y reflujo de toda la temporada salta a la vista: el año en que los Warriors y los Cavaliers se enfrentaron en las Finales su Elo alcanzó el pico a la vez; que el Oeste sea en conjunto más duro que el Este se refleja en el Elo extra que los Warriors acumularon de "victorias de calidad"; y las pérdidas de plantilla y lesiones tras un título hacen que la curva caiga igual de rápido.
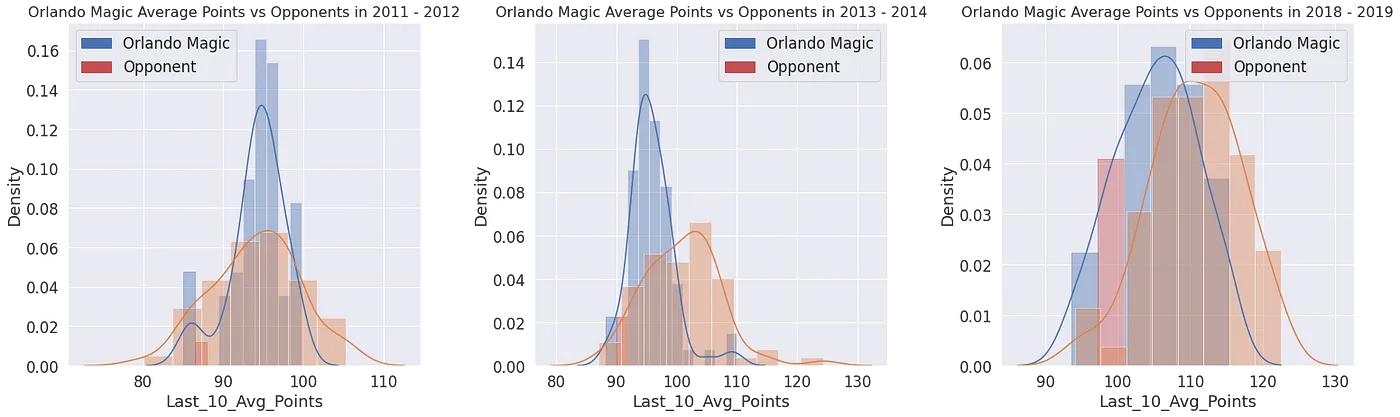
2. Forma reciente del equipo (promedio de los últimos 10 partidos)
Promedia los últimos 10 partidos de cada equipo en puntos, rebotes, asistencias, pérdidas, tapones y robos, y guárdalos como nuevas columnas de características. El arte está en la selección de características: usa análisis de correlación, análisis de componentes principales (PCA) e información ganada para conservar las columnas más informativas. Para captar además la tendencia y la estacionalidad, superpón modelos de series temporales (ARIMA, LSTM), o pasa las características directamente a un SVM, un árbol de decisión o un random forest para que aprendan las relaciones no lineales entre ellas.
3. Forma reciente del jugador (promedio de los últimos 10 partidos)
Más allá del nivel de equipo, la forma reciente de cada jugador también es una señal. Tras extraer el detalle partido a partido de nba.com/stats, calcula un promedio de los últimos 10 partidos para cada jugador. Tomemos dos estrellas como ejemplo:
| Jugador | PTS | REB | AST | TOV | BLK | STL |
|---|---|---|---|---|---|---|
| LeBron James | 28.5 | 7.8 | 7.2 | 2.3 | 1.1 | 1.5 |
| Stephen Curry | 31.2 | 5.6 | 6.8 | 2.1 | 0.3 | 1.7 |
Distintos jugadores muestran su valor en columnas distintas (un anotador frente a un pívot reboteador), y la selección de características de nuevo se guía por el análisis de correlación, el PCA y la información ganada.
4. Rendimiento del jugador en la temporada (anterior y actual)
Los promedios por sí solos distorsionan el panorama — los jugadores se lesionan y rotan, así que al modelo le importa más cuánto se desvía cada partido de la línea base del propio jugador. Una evaluación completa debe ponderar cinco dimensiones a la vez:
Estadísticas promedio de box score
Puntos, asistencias, rebotes, robos, tapones y pérdidas — léelos siempre junto a la posición y el esquema para que los números superficiales no te engañen.
Estado de lesiones
La zona lesionada y el tiempo de recuperación previsto determinan directamente la disponibilidad y las variaciones de forma tras el regreso — una entrada clave del modelo.
Minutos jugados
La diferencia de minutos entre titulares y suplentes infla o comprime las estadísticas brutas; gran producción en pocos minutos indica alta eficiencia.
Posición y estilo de juego
Un escolta y un pívot cumplen funciones distintas, y el esquema del equipo (circulación de balón vs. aislamiento) reconfigura las estadísticas.
Contexto del partido
Administrar una ventaja ralentiza el ritmo y reduce las estadísticas, mientras que remontar un déficit las infla — el contexto de victoria/derrota debe tenerse en cuenta.
5. Índice de eficiencia del jugador (PER)
Igual que el Elo hace para los equipos, el PER de Hollinger reúne estadísticas aparentemente inconexas en un único índice que "relativiza" el rendimiento del jugador. Las estadísticas de la NBA se inflan o comprimen fácilmente por los minutos y el emparejamiento (suplente vs. titular), y el PER lo corrige con una normalización por minuto — ponderando cada estadística ofensiva y defensiva y multiplicando luego por la inversa de los minutos jugados:
PER = ( FGM × 85.910 + STL × 53.897 + 3PTM × 51.757
+ FTM × 46.845 + BLK × 39.190 + OREB × 39.190
+ AST × 34.677 + DREB × 14.707 − PF × 17.174
− FT_Miss × 20.091 − FG_Miss × 39.190 − TOV × 53.897
) × (1 / Minutes)Análisis de datos y entrenamiento del modelo
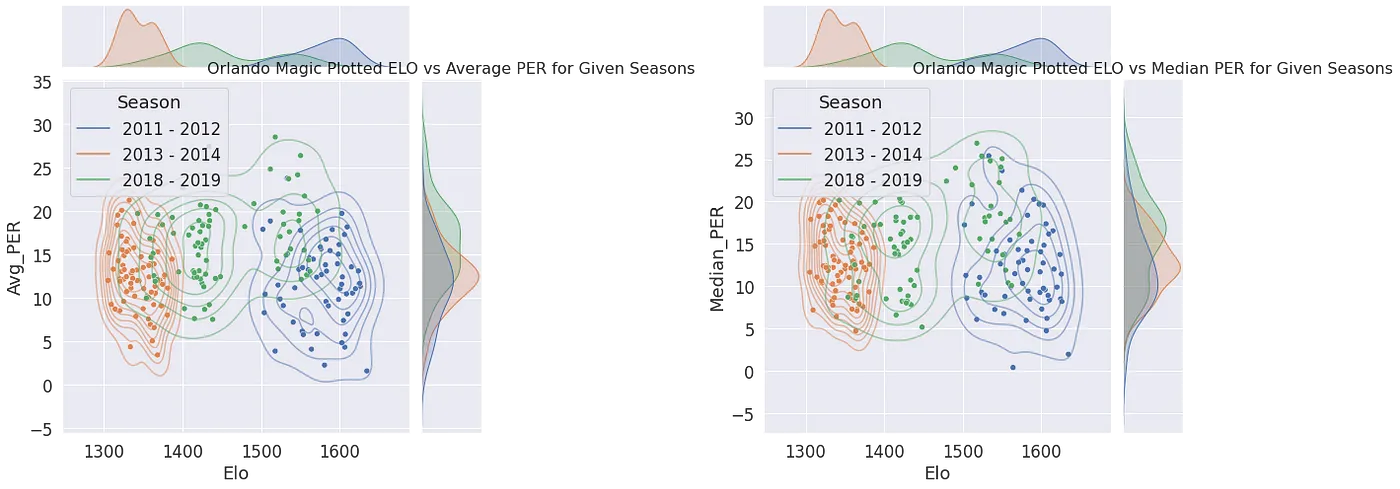
Dos preguntas están en el centro del análisis: ¿el Elo se correlaciona realmente con las demás estadísticas y se alinea correctamente? ¿Y predecir los resultados de los partidos funciona mejor con estadísticas de equipo (Elo) o con estadísticas de jugador (PER)?
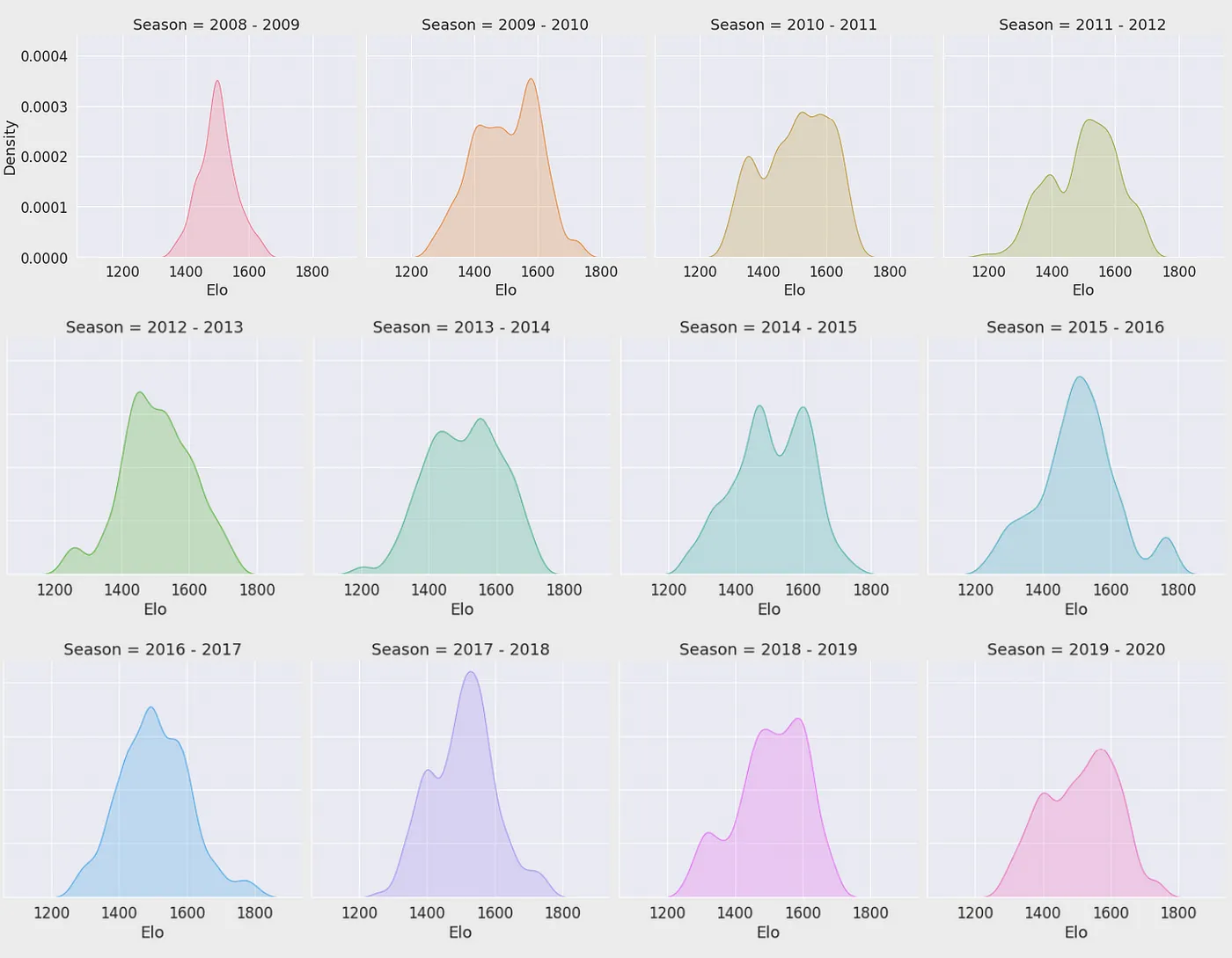
Empieza con la densidad de distribución del Elo de toda la liga en cada temporada: una forma casi normal significa una liga equilibrada, mientras que una cola larga significa que ha surgido un "superequipo". Sigue a un solo equipo y cuanto mayor sea su anotación media, más alto tiende a ser su Elo — sin embargo, a niveles de anotación similares el Elo sigue variando mucho; solo cuando haces la anotación relativa al rival y a la media de la liga la correlación se estabiliza de verdad. Esa es la prueba de que el Elo predice los resultados mejor que los puntos brutos precisamente porque es una estadística relativizada. El PER cuenta la historia opuesta: alinea la suma, la media y la mediana del PER de un equipo frente a la fuerza del equipo que mide el Elo, y la correlación es débil en todos los casos — una alta eficiencia de los jugadores no significa más puntos, y lo que realmente decide un enfrentamiento (y a su vez impulsa el Elo) es la anotación relativa.
Dos conclusiones clave
- La relativización es lo que lo hace estable: solo cuando la anotación se expresa en relación con el rival y la liga su correlación con los resultados se sostiene de verdad.
- Equipo > suma de jugadores: la suma del PER se correlaciona débilmente con la fuerza del equipo — una alta eficiencia de los jugadores no significa que el equipo gane.
Precisión de prueba frente al techo teórico
Los mejores modelos de predicción de la NBA llegan como máximo a cerca del 70%; con 67.15% el bosque aleatorio ya se está acercando — las mejoras restantes están en la elección del modelo, no en el ajuste.
Al predecir los resultados a partir de la anotación de los jugadores, usamos regresión lineal (que predice una puntuación continua) en lugar de regresión logística (que solo predice victoria/derrota), y luego sumamos los puntos previstos de cada equipo para compararlos. La precisión del 58,66% confirma la observación anterior: el rendimiento combinado de los jugadores es demasiado variable, ni de lejos tan consistente como la forma a nivel de equipo. El mejor resultado — un random forest ajustado con RandomizedSearchCV — alcanzó una precisión máxima de prueba del 67,15%, y dado que incluso los modelos de predicción más potentes de la NBA topan en torno al 70%, el modelo ya se acerca al techo teórico. A partir de aquí, el rendimiento llega de invertir tiempo en la elección del modelo (clasificador SGD, análisis discriminante lineal, redes convolucionales, naive Bayes) en lugar de afinar sin fin.
Comparación de cuotas: de la tasa de acierto prevista al EV positivo
La tasa de acierto de un modelo por sí sola no genera dinero; la fórmula del beneficio necesita tres ingredientes: la tasa de acierto prevista por el aprendizaje profundo, las cuotas en vivo y una estrategia de apuestas validada con backtest. Confronta la tasa de acierto de la IA con las cuotas del mercado para calcular el valor esperado (EV), y actúa solo cuando el EV sea positivo:
EV = (tasa de victoria de la IA × cuota decimal) − 1 EV > 0 → retorno esperado positivo a largo plazo (apuesta de valor) EV < 0 → perdedora a largo plazo, omítela Ejemplo: tasa de victoria de la IA 58%, cuota 1.90 EV = (0.58 × 1.90) − 1 = +0.102 → +10.2% esperado por apuesta
Este enfoque no se limita a la NBA: se aplica por igual al baloncesto, el béisbol, el fútbol, el hockey y el tenis. Puedes revisar la tasa de acierto del modelo y las unidades ganadas en partidos reales mes a mes enRendimiento del Modelo de IAy realizar cálculos rápidos de valor esperado previo a la apuesta y de cuotas de combinadas con laCalculadoras de Apuestas.
Un solo marco que abarca las grandes ligas del mundo
Como la ingeniería de características consiste en comparar capacidad en lugar de leer nombres de equipos, el mismo pipeline se traslada entre deportes: actualmente cubre la NBA, la MLB, las cinco grandes ligas de fútbol, las competiciones europeas y la NHL, con más ligas por venir.
 NBA
NBA MLB
MLB EPL
EPL La Liga
La Liga Bundesliga
Bundesliga Serie A
Serie A Ligue 1
Ligue 1 UCL
UCL UEL
UEL MLS
MLS NHL
NHL
Conclusión y próximos pasos
- Las estadísticas relativizadas superan a los números brutos: el Elo es más preciso que el promedio de puntos, y los puntos superan al PER sumado, porque ganar es relativo por naturaleza.
- Las características a nivel de equipo son más estables que la suma de los jugadores y constituyen la señal principal del modelo; la forma del jugador funciona como característica de apoyo.
- Una precisión de prueba del 67,15% ya se acerca al techo teórico de aproximadamente el 70% para la predicción en la NBA; las mejoras restantes están en la elección del modelo, no en un ajuste interminable.
- Una tasa de victorias predicha solo se convierte en beneficio a largo plazo cuando se combina con la comparación de cuotas y la disciplina de EV positivo.
Referencias y fuentes de datos
Todos los métodos y conjuntos de datos de este artículo son verificables públicamente; no dudes en profundizar en la investigación original:
- El sistema de puntuación Elo (Arpad Elo, 1978)
- Calificación de Eficiencia del Jugador, PER (John Hollinger)
- Dixon & Coles (1997): un modelo de Poisson para los goles en el fútbol
- La distribución de Poisson (modelado del recuento de anotaciones)
- scikit-learn: bosques aleatorios y ajuste con RandomizedSearchCV
- Fuentes de datos: Basketball-Reference · stats.nba.com
Ahora que entiendes el algoritmo, gestiona tus propias apuestas con datos
Registra cada apuesta gratis y haz un seguimiento automático de tu tasa de aciertos, ROI y curva de capital, para que puedas backtestear tu propia estrategia de apuestas igual que lo hace un modelo.